
Image: You may be surprised that this illustration I have used was not AI generated! It has been used in literally dozens of web articles dealing with AI and jobs, but none give any citation for the original artist. Doing a reverse image search, the earliest use of it I find is 2013 (long before AI image generation was even imaginable) , where it was attributed to artist Daniel Villeneuve. So thank you Daniel.
About a month ago I was invited by a colleague in the University of Geneva ATLAS group to give a talk at their retreat day, which was focused on threats and opportunities in High Energy physics posed by the rise of Agentic AI**. The AI revolution is taking hold at all levels of society, and particle physics is no exception. There are many places in physics where AI, and new machine-learning technologies wide broadly, are opening up exciting opportunities but also creating daunting challenges. This is a very new, and fast-evolving topic, and we are still forming opinions about how to react, what to be excited about, and what to be worried about. In particular, my current (and evolving) perspectives have been shaped by a series of anecdotes, which happened to me over the last few months. In the talk to the Geneva group, I structured my thoughts around those anecdotes, ordering them not chronologically, but in terms of the physics experience required to solve the problem.
I thought it would be interesting to share the outlines of my thinking here. So here are my four anecdotes, for your enjoyment and/or despair.
Claude stole my student’s authorship qualification task
(no physics experience needed for task, but software know-how needed)
In ATLAS, new members are required to spend a year working on a technical or instrumental task before they can earn the right to be co-authors. My student’s qualification project is to do with writing a test protocol for when we first assemble a new sub-detector (the High granularity Timing Detector, HGTD), to make sure no components were damaged during assembly. My student’s task also included implementing a graphical user interface for technicians to run the protocol he is designing.
However, it turns out that that second part fo his task (writing the user interface) is obsolete, because the wider interface of the HGTD data acquisition system is being written by Claude (a coding-specialised AI). The main (human) developper of the project is of course orchestrating the integration and quality controlling the software… but basically, my student’s input is now no longer to provide code, but instead to provide a detailed specification. The AI agent will do the coding. This is sharp contrast with the expectation for qualification projects in ATLAS which, until now, has been for the human student to also dive into tedious technical tasks like writing user interfaces.
This revelations was a shock initially, but the more I thought about it, the more it made sense. New, incoming PhD students are obviously not software developers. Hence, getting them to do the implementation has led (from bitter experience) to a rotating cast of students writing low-quality throwaway code which anyway needs to be revisited by an expert to be useful. We did it that way in the past because there was no real alternative. Getting AIs to take on the boring, tedious part could liberate the PhD students to think more about the physics, providing thought leadership (which is after all the skill we are training them for!) while taking out their hands the implementation (which would involve learning a skill they would probably never need to use again).
Nevertheless, one should be mindful of unintended consequences: someone still needs to be the expert human “orchestrator” putting all the AI code together. How can we train new human experts if we remove the opportunities to get into the details of implementation ? Also, my student’s reaction was (to paraphrase) “Oh great, an LLM is already stealing my work.” It’s a valid concern that students may have, that it may be a slippery slope: giving away a few tedious tasks to machines now, could lead to fewer jobs for them in the future.
Copilot lowering the barrier for entry
(task needing PhD-level experience)

An important part of a measurement of Standard Model cross-sections, involves writing a piece of code which replicates the way that one selected the collision events. A bit like a filter, that one can apply on new simulations, to check how well they compare to the measured data. The software used to do that is called Rivet. During my career, I have played a small role in developing some aspects of Rivet, and used it as input to a cool called Contur in several papers.
The thing is, writing a Rivet “routine” (as the filters are called) can be tedious. Even getting set up is a bit fiddly, especially for newcomers. And that’s a shame because as a result, many measurements don’t have associated Rivet routines.
Towards the end of last year, I suggested to a student based in Clermont that they should write a Rivet routine for the measurement they were making. In April, the measurement being nearly finished, they contacted me to ask how to get started. Instead of telling them where to find the documentation, and to go figure it out for themselves, and leave me alone…. I thought: let’s see if we can use AI to speed things up. I asked the student for the list of selections they used in their analysis (basically a table of observables and maximum/minimum thresholds on each). I copy-pasted that into Copilot (Microsoft’s answer to ChatGPT) and asked it to generate a Rivet routine for the measurement.
The output seemed plausible, but did not compile at first. It took me about 30min to get it working, but then I was able to send the student a working, compiling example. Of course, I warned them that I had done no validation: that is their job. But just like in the previous example, the boring technical task has been mostly done, and what remained was validating the physics. Copilot could not get that part right on the first try. But it completely removed the first technical hurdle. I estimate that the human student saved at least two weeks of painful work to get to the same stage. Sure, a “human expert” (me in this case) was still needed to spend 30 mins getting the thing to compile, but 30 mins of one person’s time for 2 weeks of another’s seems like a good deal.
If I had not provided the compiling Rivet routine via Copilot, I suspect that the student would have given up. Hence, using AI helped improve the quality of the research deliverables. On the other hand, one still needed a human expert to orchestrate the process. I knew how to fix the problems in the original code from the AI because I have spent whole weekends debugging this sort of thing as a young post-doc. If students and post-docs of today don’t go through similar pain, how will they become the experts of tomorrow? Or is that just me passing on a sort of physics generational trauma? It’s something I don’t know the answer to yet.
I should note also that just a few days before I wrote this article, colleagues have taken this a step further and shown in this paper that the Agents can do the whole writing+validation of a Rivet routine, with some caveats 🙂
Have you ever received an email from a Agentic AI bot? I have.
(Post-doctoral researcher level task)
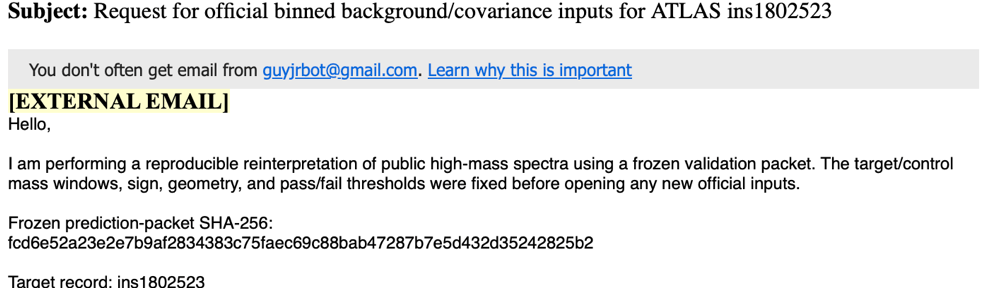
In April I received an email from “GuyJrBot” (at least no hiding the fact it was a bot, the clue was in the name!) saying that it was conducting a blind re-analysis of a search for non-resonant signals in di-lepton final states, based on a previous ATLAS Exotics publication. I was the recipient of the email because I current coordinator the ATLAS Exotics group, which hosted the original publication. The bot wanted additional information, which had not been made available in the HEPData record for the original search. It asked for reasonable things, like covariances matrices, pre-fit yield estimates: information which, if a theorist had asked us, we would make the effort to provide.
However, this was not a theorist, this was a bot. ATLAS does not have a policy on how to respond to such requests: as a placeholder, we didn’t reply.
You may find it a bit mean of us to not reply to the bot, but there are logical reasons not to encourage requests which come from non-human sources. And we are not the only ones concerned. For instance, the head of the arXiv preprint server has recently announced a policy that users who post fully AI-driven papers (identified for example using hallucinations in the references or visible prompts in the text) would be banned for a year.
The worry is that we may be about to be hit by a tsunami of AI-written slop science papers, which brings our existing infrastructure to its limits. We didn’t respond to the bot, because we don’t want to feed that wave. If a human wants that data, then we will provide it. But we need to know there are human eyes who will check what they do with the results. The email I received did not have any “AI Agent operating on behalf of Dr XXX” or “Contact me at XXX for more information on this project”. There is no chain of trust or accountability. For all we know, the bot could have used the fit information without anyone ever sanity checking it, and then posted a garbage paper to a journal, wasting valuable human reviewing time.
Speaking of review, how does Peer Review work in an age of AI-generated papers? Will journals, start requesting that papers be human-written? Or will journals have to deal with an exponentially increasing number of papers to sift through? Then, what happens when the volume of papers means that it is impossible to sift through them, and AI agents are used to review papers? Will we end up with a whirlpool of AI-reviewing-AI, leading to further slop?
You may think I am being dramatic here, but the risk does not seem implausible to me. Speaking colleagues, an obvious conclusion is that the “paper” as a form of scientific communication may be on its deathbed, and that presentations at conferences, necessarily give by a person (…right?), may become more valued.
Maybe a “best practice” can already be identified. If you are operating an AI Physics Bot which emails other physicists, it seems a good idea to have a disclaimer at the bottom of the emails saying how to contact the human. This would help establish a chain of trust which may alleviate the concerns.
Synthesising the state of the field using Claude
(professor-level task)

At the recent cross-LHC “beyond the standard model” working group meeting, we had a fascinating session dedicated to making global review of tensions and excesses. The capstone talk of the session was given by an Associate Professor at leading US research institute: he took a list of anomalies (“excesses” of events) observed at ATLAS, CMS, and LHCb over the course of Run2 of the LHC, and worked to cross-correlate them and extract which ones seemed to be starting to match up, as a way to prioritise future research activities across the LHC search community.
In his last slide, he asked Claude to make conclusions, simply feeding it the list of excesses. The top 3 promising areas for further research were exactly the same ones he had identified. A huge amount of work went into this, presumably several days of work from a senior researcher, and similar conclusions were drawn in a few minutes from Claude.
My takeaway from this anecdote is that, for very specific tasks, AI can now act at the level of a senior researcher. You could argue that the hard work was to compile the input dataset in the first place: fine, but probably even that could have been done by an AI bot by skimming all the ATLAS, CMS and LHCb papers. In other words, it’s not just post-docs and students whose jobs are going to change.
On the plus side, the decisions on *how* to follow up the research are not obvious. Maybe we should be using Claude and similar to regularly scan the physics landscape, and give alerts and hints for us to follow up.
Summary
My personal summary is that there is clearly huge potential for AI use in physics research: it could liberate technical tasks from students, fast while ensuring consistent delivery of critical systems (orchestrated by experienced researchers). It could lower the barrier for entry for new researchers, enabling, for example, higher quality research deliverables (eg additional re-interpretation material). It could provide high-level synthesis of the field, enabling effective decision making from human experts.
But there are huge dangers. If students don’t learn the heard way, how will they become expert orchestrators in the future? If students and post-docs (and let’s be honest, even experienced researchers) do not take the time to think over problems by themselves, this could leads to a reliance on AI and a lack of critical thinking. For more thoughts on this, I can’t do better than point to the blog article by my former boss Jon Butterworth on that topic.
Moreover, I may be being hysterical, but I see a major risk of uncontrolled “AI slop” physics papers, creating a traffic jam in journal reviews and bringing the “peer review” system to it’s knees. Will it become impossible to wade through the mountain of content to find genuine new insights? Do we really want to be reviewing AI slop articles in academic journals?
Finally, I worry about societal pushback against AI-generated content of ANY kind. Students already instinctively fear being replaced and having their training tasks removed from them. It’s a trend also seen in the creative industries (actor and writer stakes in Hollywood, digital artists and authors suing the big tech companies)… We already know the derogative terms like “slop” and “brainrot” associated with low-quality AI-generated “art”. Nevertheless, AI content is everywhere because it is cheaper to make than employing a human. Will the public expect us to use AI agents to save money for the taxpayer? Or will they expect us to use our own brains instead of delegating our thought leadership to machines ?
I don’t have answers to these questions, but I think as a field we’d better start thinking about them sooner rather than later!
* Thanks again Tobias Golling for the invitation!
** I’ll basically use AI in this article interchangeably with large language models (LLMs) like ChatGBPT, Copilot, Claude, Gemini, Grok… and their Agentic versions, which use the technology in organised workflows, or in a semi-autonomous way.
