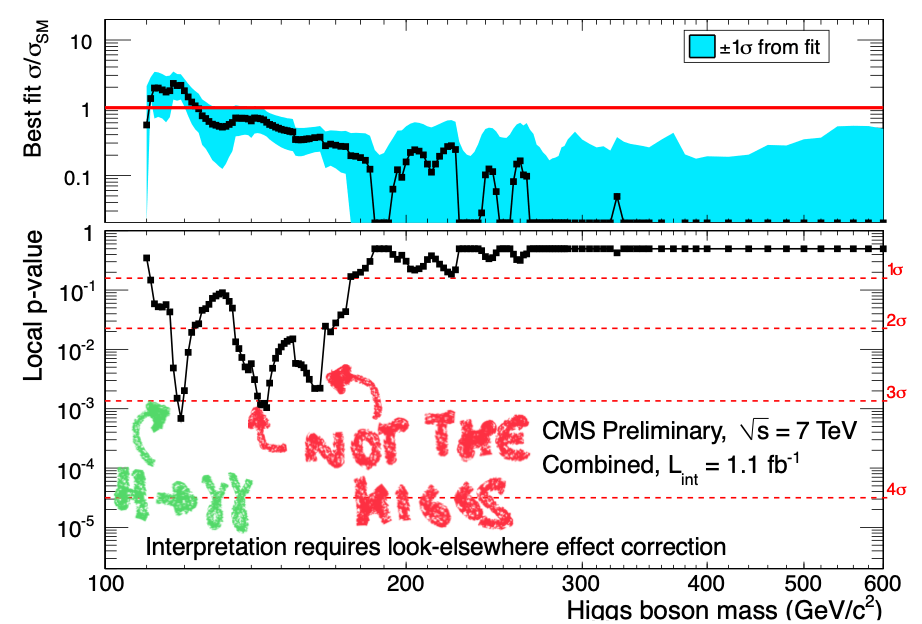
Image: A fascinating plot from the days where the first hints of the Higgs boson started to appear in early LHC data by CMS [Publication]. In addition to the actual Higgs boson peak, the plot shows “evidence” (at the 3σ level) for two other particles, with masses around 140 and 170 GeV). These turned out to be “1 in 300” statistical fluctuations which disappeared with more data, and of which no one speaks these days. Markup by to Roberto Franceschini in this talk.
Ok, full disclosure, this is going to be a post about statistics. But I’m going to try really hard to make it seem like it’s not about statistics. Trust me, keep reading, and at the end, you can tell me if I succeeded.
Discovering a new particle is a bit like checking if your bother is cheating at dungeons and dragons by using loaded dice. He KEEPS GETTING SIXES. Not every time, but often enough that he manages to dodge the fire-breathing dragon’s attack, or manages to sneak past the guards at the entrance of the dungeon. He insists it’s normal a normal dice. You really want to know if he is cheating or if he’s just lucky.
What can you do to avoid a family argument ?
Well, you can ask him to throw the the die 100s of times, and see if you get on average roughly the same numbers of 1, 2, 3, 4, 5 and 6. If it’s a fair die, you should get roughly equal proportions. If your brother is cheating, you should start seeing a higher proportion of sixes. At some stage, after hundreds of throws, if there are loads more 6’s than other numbers, you can claim with some degree of confidence that your brother is a cheat (or that he is innocent). The more times you throw, the higher the confidence.
Discovering a new particle is similar: if you want to know whether the Higgs boson exists or not, you check thousands of collisions (each collision is like a roll of the dice), and you check the distribution of invariant masses of the outgoing particles (this corresponds to the 1, 2, 3….6 from the dice throw). If one of the results comes out more often than you expect (like having more 6’s than you expect), after some threshold of confidence, you can claim discovery.
The thresholds we usually set for initial evidence of a new particle is that you’d have less than a roughly 1 in 300 chance of getting the same result by chance (a “3σ excess”, in the jargon). That’s something like the chance of rolling 3 or 4 sixes in a row.. Seems pretty safe, right?
By what if your argument with your brother was repeated on a daily basis for a year ? If you repeated your test each day, that’s 365 chances. On average, on one of those days, you should get your 3 or 4 sixes in a row, even if your brother is not a cheat: you had a 1 in 300 chance, and you tried roughly 300 times, to it should happen roughly once. You are at risk of making a false accusation, and tearing the family apart!
Now consider that new technologies like Anomaly Detection (a branch of machine learning) and to some extend Artificial Intelligence, are allowing us to perform searches for new particles on a massive scale. Instead of searching for one new theory at a time, you can try to generically scan hundreds of different combinations of different objects to build you invariant mass distributions. And each of those distributions comprises of hundreds of independent mass bins. For example, we have ongoing search in Exotics which is attempting to scan thousands of combinations. That means that our usual threshold for evidence should be reached several times, even in the absence of a new particle. Yet, we don’t want to make undue claims to the media about discovering new particles which turn out not to exist. That’s bad for our credibility.
This is known as the “Look Elsewhere Effect”: if you look elsewhere (try again) enough times, you will eventually get any result, no matter how rare. It was already something people worried about at the time of the Higgs boson discovery. But now it’s much more urgent to have robust methods to deal with it because technological advances are allowing us perform searches on a much more massive scale.
The simple solution to the Look Elsewhere Effect is that one should determine in advance how likely it is to get an false positive “evidence” or “discovery” result from a given search, and then downgrade the significance of the reported result accordingly. The raw result is called the “local significance” and the downgraded one is called “global significance”. The issue is that the only truly reliable way to calculate this is to simulate the experiment large numbers of times (potentially billions and billions), which is tedious and computationally expensive. I’m sure you can imagine that sitting at the table with your brother rolling the dice hundreds of times a day for a year does not sounds like a very relaxing way to spend your evenings. So it’s an area of active research to determine reliable approximations to speed this up. We had a lively cross-LHC meeting on this topic only a month ago, and a follow up just last week, when trying to wade through the list of “evidence” results reported by any LHC collaboration, to see if there are any consistent hints of new physics in our combined data.
The question of the global significance is just another way in which the machine learning technological resolution is forcing us to revisit our practices.
It may surprise you to learn that some of the most important discoveries in particle physics, for example the discovery of the Z-boson, would not have passed our statistical criteria today. The chance of that discovery being a fluke was only something like 1 in 100. It may re-assure you that our modern threshold for discovery is “less than a 1 in 3.5 million” chance of a false positive (a “5σ excess”, in the jargon). That’s like rolling 8 or 9 sixes in a row. But today, we are in uncharted territory, especially if and when agentic AI bots start performing their own searches on ATLAS and CMS open data (which is already starting to happen). It’s entirely possible that the number of regions explored in this programmatic way starts to number in the millions, in which case we start to be at serious risk of false discoveries. We need to start planning our statistical tools how to make sure that we do not rubbish the field’s credibility. The good news is that we are on it 🙂
If you made it this far: did I manage to make a post about statistics interesting enough to keep your attention ?
This article was 100% human generated, written without any AI help, all typos and grammar mistakes are my own 🙂

learning about new flaws in AI is strangely comforting, but only if we have the collective will to focus on the limitations of the technology. Sadly, its convenience, affordability and adequate reliability for most applications will make it broadly accepted and believed. We are indeed doomed!
LikeLike